The Advancements in State-of-the-Art Language Models
A look into the latest breakthroughs and progressions in the field of large language models, and what the future holds.

In case you haven’t heard, artificial intelligence is the hot new thing.
Generative AI seems to be on the lips of every venture capitalist, entrepreneur, Fortune 500 CEO and journalist these days, from Silicon Valley to Davos.
To those who started paying real attention to AI in 2022, it may seem that technologies like ChatGPT and Stable Diffusion came out of nowhere to take the world by storm. They didn’t.
Back in 2020, we wrote an article in this column predicting that generative AI would be one of the pillars of the next generation of artificial intelligence.
Since at least the release of GPT-2 in 2019, it has been clear to those working in the field that generative language models were poised to unleash vast economic and societal transformation. Similarly, while text-to-image models only captured the public’s attention last summer, the technology’s ascendance has appeared inevitable since OpenAI released the original DALL-E in January 2021. (We wrote an article making this argument days after the release of the original DALL-E.)
By this same token, it is important to remember that the current state of the art in AI is far from an end state for AI’s capabilities. On the contrary, the frontiers of artificial intelligence have never advanced more rapidly than they are right now. As amazing as ChatGPT seems to us at the moment, it is a mere stepping stone to what comes next.
What will the next generation of large language models (LLMs) look like? The answer to this question is already out there, under development at AI startups and research groups at this very moment.
This article highlights three emerging areas that will help define the next wave of innovation in generative AI and LLMs. For those looking to remain ahead of the curve in this fast-changing world—read on.
1) Models that can generate their own training data to improve themselves.
Consider how humans think and learn. We collect knowledge and perspective from external sources of information—say, by reading a book. But we also generate novel ideas and insights on our own, by reflecting on a topic or thinking through a problem in our minds. We are able to deepen our understanding of the world via internal reflection and analysis not directly tied to any new external input.
A new avenue of AI research seeks to enable large language models to do something analogous, effectively bootstrapping their own intelligence.
As part of their training, today’s LLMs ingest much of the world’s accumulated written information (e.g., Wikipedia, books, news articles). What if these models, once trained, could use all the knowledge that they have absorbed from these sources to produce new written content—and then use that content as additional training data in order to improve themselves? Initial work suggests that this approach may be possible—and powerful.
In one recent research effort, aptly titled “Large Language Models Can Self-Improve,” a group of Google researchers built an LLM that can come up with a set of questions, generate detailed answers to those questions, filter its own answers for the most high-quality output, and then fine-tune itself on the curated answers. Remarkably, this leads to new state-of-the-art performance on various language tasks. For instance, the model’s performance increased from 74.2% to 82.1% on GSM8K and from 78.2% to 83.0% on DROP, two popular benchmarks used to evaluate LLM performance.
Another recent work builds on an important LLM method called “instruction fine-tuning,” which lies at the core of products like ChatGPT. Whereas ChatGPT and other instruction fine-tuned models rely on human-written instructions, this research group built a model that can generate its own natural language instructions and then fine-tune itself on those instructions. The performance gains are dramatic: this method improves the performance of the base GPT-3 model by 33%, nearly matching the performance of OpenAI’s own instruction-tuned model.
In a thematically related work, researchers from Google and Carnegie Mellon show that if a large language model, when presented with a question, first recites to itself what it knows about the topic before responding, it provides more accurate and sophisticated responses. This can be loosely analogized to a human in conversation who, rather than blurting out the first thing that comes to mind on a topic, searches her memory and reflects on her beliefs before sharing a perspective.
When people first hear about this line of research, a conceptual objection often arises—isn’t this all circular? How can a model produce data that the model can then consume to improve itself? If the new data came from the model in the first place, shouldn’t the “knowledge” or “signal” that it contains already be incorporated in the model?
This objection makes sense if we conceive of large language models as databases, storing information from their training data and reproducing it in different combinations when prompted. But—uncomfortable or even eerie as it may sound—we are better off instead conceiving of large language models along the lines of the human brain (no, the analogy is of course not perfect!).
We humans ingest a tremendous amount of data from the world that alters the neural connections in our brains in imponderable, innumerable ways. Through introspection, writing, conversation—sometimes just a good night’s sleep—our brains can then produce new insights that had not previously been in our minds nor in any information source out in the world. If we internalize these new insights, they can make us wiser.
The idea that LLMs can generate their own training data is particularly important in light of the fact that the world may soon run out of text training data. This is not yet a widely appreciated problem, but it is one that many AI researchers are worried about.
By one estimate, the world’s total stock of usable text data is between 4.6 trillion and 17.2 trillion tokens. This includes all the world’s books, all scientific papers, all news articles, all of Wikipedia, all publicly available code, and much of the rest of the internet, filtered for quality (e.g., webpages, blogs, social media). Another recent estimate puts the total figure at 3.2 trillion tokens.
DeepMind’s Chinchilla, one of today’s leading LLMs, was trained on 1.4 trillion tokens.
In other words, we may be well within one order of magnitude of exhausting the world’s entire supply of useful language training data.
If large language models are able to generate their own training data and use it to continue self-improving, this could render irrelevant the looming data shortage. It would represent a mind-bending leap forward for LLMs.
2) Models that can fact-check themselves.
A popular narrative these days is that ChatGPT and conversational LLMs like it are on the verge of replacing Google Search as the world’s go-to source for information, disrupting the once-mighty tech giant like Blockbuster or Kodak were disrupted before it.
This narrative badly oversimplifies things. LLMs as they exist today will never replace Google Search. Why not? In short, because today’s LLMs make stuff up.
As powerful as they are, large language models regularly produce inaccurate, misleading or false information (and present it confidently and convincingly).
Examples abound of ChatGPT’s “hallucinations” (as these misstatements are referred to). This is not to single out ChatGPT; every generative language model in existence today hallucinates in similar ways.
To give a few examples: it recommends books that don’t exist; it insists that the number 220 is less than 200; it is unsure whether Abraham Lincoln’s assassin was on the same continent as Lincoln at the time of the assassination; it provides plausible-sounding but incorrect explanations of concepts like Bayes’ Theorem.
Most users will not accept a search engine that gets basic facts like these wrong some of the time; even 99% accuracy will not be good enough for broad market adoption. OpenAI CEO Sam Altman himself acknowledges this, recently cautioning: “ChatGPT is incredibly limited, but good enough at some things to create a misleading impression of greatness. It's a mistake to be relying on it for anything important right now.”
It is an open question whether LLMs’ hallucination problem can be solved via incremental improvements to existing architectures, or whether a more fundamental paradigm shift in AI methodologies will be necessary to give AI common sense and real understanding. Deep learning pioneer Yann LeCun, for one, believes the latter. LeCun’s contrarian perspective may prove correct; time will tell.
In the nearer term, though, a set of promising innovations offers to at least mitigate LLMs’ factual unreliability. These new methods will play an essential role in preparing LLMs for widespread real-world deployment.
Two related capabilities lie at the heart of current efforts to make language models more accurate: (1) the ability for LLMs to retrieve information from external sources, and (2) the ability for LLMs to provide references and citations for the information they provide.
ChatGPT is limited to the information that is already stored inside of it, captured in its static weights. (This is why it is not able to discuss events that occurred after 2021, when the model was trained.) Being able to pull in information from external sources will empower LLMs to access the most accurate and up-to-date information available, even when that information changes frequently (say, companies’ stock prices).
Of course, having access to an external information source does not by itself guarantee that LLMs will retrieve the most accurate and relevant information. One important way for LLMs to increase transparency and trust with human users is to include references to the source(s) from which they retrieved the information. Such citations allow human users to audit the information source as needed in order to decide for themselves on its reliability.
Important early work in this field includes models like REALM (from Google) and RAG (from Facebook), both published in 2020. With the rise of conversational LLMs in recent months, research in this area is now rapidly accelerating.
Last year, OpenAI published a fine-tuned version of its GPT model named WebGPT that can browse the internet using Microsoft Bing in order to provide more accurate and in-depth responses to prompts. WebGPT navigates the internet much like a human does: it can submit search queries to Bing, follow links, scroll up and down on webpages, and use functions like Ctrl+F to find terms. When the model finds relevant information on the internet that it incorporates into its output, it provides citations so that the human user can see where the information came from.
The results are encouraging: for the same query, WebGPT’s responses are preferred to responses written by human subjects 56% of the time and are preferred to the highest-rated responses on Reddit 69% of the time.
DeepMind is also pursuing research along these lines. A few months ago, DeepMind published a new model named Sparrow. Like ChatGPT, Sparrow is dialogue-based; like WebGPT, it can search the internet for information and provide citations for its assertions. Sparrow builds on important earlier work out of DeepMind including SpaLM, RETRO and GopherCite.
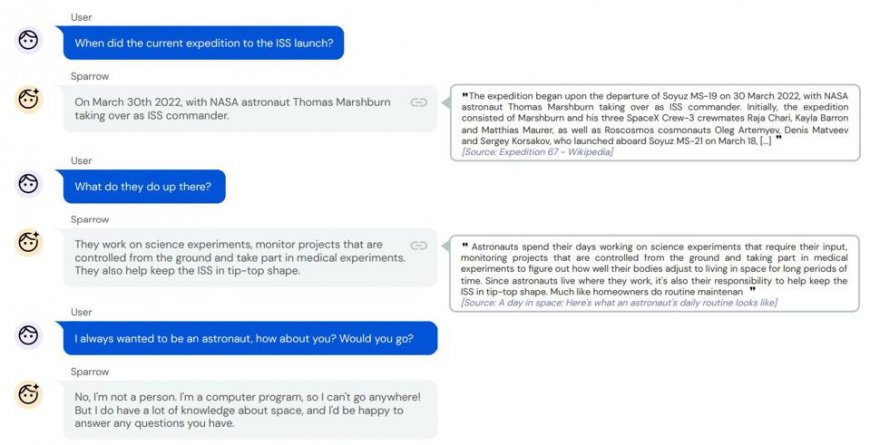
The DeepMind researchers find that Sparrow’s citations are helpful and accurate 78% of the time—suggesting both that this research approach is promising and that the problem of LLM inaccuracy is far from solved.
Younger startups including You.com and Perplexity have also recently launched LLM-powered conversational search interfaces with the ability to retrieve information from external sources and cite references. These products are available for public use today.
LLMs’ greatest shortcoming is their unreliability, their stubborn tendency to confidently provide inaccurate information. Language models promise to reshape every sector of our economy, but they will never reach their full potential until this problem is addressed. Expect to see plenty of activity and innovation in this area in the months ahead.
3) Massive sparse expert models.
Today’s most prominent large language models all have effectively the same architecture.
Meta AI chief Yann LeCun said recently: “In terms of underlying techniques, ChatGPT is not particularly innovative. It’s nothing revolutionary, although that’s the way it’s perceived in the public. It’s just that, you know, it’s well put together, it’s nicely done.”
LeCun’s statement stirred up plenty of controversy and Twitter debate. But the simple fact is that he is correct, as no serious AI researcher would dispute.
All of today’s well-known language models—e.g., GPT-3 from OpenAI, PaLM or LaMDA from Google, Galactica or OPT from Meta, Megatron-Turing from Nvidia/Microsoft, Jurassic-1 from AI21 Labs—are built in the same basic way. They are autoregressive, self-supervised, pre-trained, densely activated transformer-based models.
To be sure, variations among these models exist: their size (parameter count), the data they are trained on, the optimization algorithm used, the batch size, the number of hidden layers, whether they are instruction fine-tuned, and so on. These variations can translate to meaningful performance differences. The core architectures, though, vary little.
Yet momentum is building behind an intriguingly different architectural approach to language models known as sparse expert models. While the idea has been around for decades, it has only recently reemerged and begun to gain in popularity.
All of the models mentioned above are dense. This means that every time the model runs, every single one of its parameters is used. Every time you submit a prompt to GPT-3, for instance, all 175 billion of the model’s parameters are activated in order to produce its response.
But what if a model were able to call upon only the most relevant subset of its parameters in order to respond to a given query? This is the basic concept behind sparse expert models.
The defining characteristic of sparse models is that they don’t activate all of their parameters for a given input, but rather only those parameters that are helpful in order to handle the input. Model sparsity thus decouples a model’s total parameter count from its compute requirements. This leads to sparse expert models’ key advantage: they can be both larger and less computationally demanding than dense models.
Why are they called sparse expert models? Because sparse models can be thought of as consisting of a collection of “sub-models” that serve as experts on different topics. Depending on the prompt presented to the model, the most relevant experts within the model are activated while the other experts remain inactive. A prompt posed in Russian, for instance, would only activate the “experts” within a model that can understand and respond in Russian, efficiently bypassing the rest of the model.
All of today’s largest LLMs are sparse. If you come across an LLM with more than 1 trillion parameters, you can safely assume that it is sparse. This includes Google’s Switch Transformer (1.6 trillion parameters), Google’s GLaM (1.2 trillion parameters) and Meta’s Mixture of Experts model (1.1 trillion parameters).
“Much of the recent progress in AI has come from training larger and larger models,” said Mikel Artetxe, who led Meta’s research on sparse models before resigning to cofound a stealth LLM startup. “GPT-3, for instance, is more than 100 times larger than GPT-2. But when we double the size of a dense model, we also make it twice as slow. Sparse models allow us to train larger models without the increase in runtime.”
Recent research on sparse expert models suggests that this architecture holds massive potential.
GLaM, a sparse expert model developed last year by Google, is 7 times larger than GPT-3, requires two-thirds less energy to train, requires half as much compute for inference, and outperforms GPT-3 on a wide range of natural language tasks. Similar work on sparse models out of Meta has yielded similarly promising results.
As the Meta researchers summarize: “We find that sparse models can achieve similar downstream task performance as dense models at a fraction of the compute. For models with relatively modest compute budgets, a sparse model can perform on par with a dense model that requires almost four times as much compute.”
There is another benefit of sparse expert models that is worth mentioning: they are more interpretable than dense models.
Interpretability—the ability for a human to understand why a model took the action that it did—is one of AI’s greatest weaknesses today. In general, today’s neural networks are uninterpretable “black boxes.” This can limit their usefulness in the real world, particularly in high-stakes settings like healthcare where human review is important.
Sparse expert models lend themselves more naturally to interpretability than conventional models because a sparse model’s output is the result of an identifiable, discrete subset of parameters within the model—namely, the “experts” that were activated. The fact that humans can better extract understandable explanations from sparse models about their behavior may prove to be a decisive advantage for these models in real-world applications.
Sparse expert models are not in widespread use today. They are less well understood and more technically complex to build than dense models. Yet considering their potential advantages, most of all their computational efficiency, don’t be surprised to see the sparse expert architecture become more prevalent in the world of LLMs going forward.
In the words of Graphcore CTO Simon Knowles: “If an AI can do many things, it doesn’t need to access all of its knowledge to do one thing. It’s completely obvious. This is how your brain works, and it’s also how an AI ought to work. I’d be surprised if, by next year, anyone is building dense language models.”